목표
- pandas를 통해 데이터를 concat/merge하기
- tidy 데이터에 대한 개념 이해
- melt와 pivot/pivot_table 함수를 사용하여 wide와 tidy 형태의 데이터를 서로 변환할 수 있다.
Pandas로 데이터 합치기

주가 데이터를 예로 들면, 종목별 데이터와 어떤 데이터가 어떤 종목을 의미하는지 설명하는 description 데이터로 나누어 질 수 있다.
효과적으로 데이터 분석을 하기위해서는 여러 개의 파일을 하나로 합쳐야한다!!!
여러 가지 방법 중 2가지를 소개해보겠당
Concat(concatenate)
간단하게 '더한다' 혹은 '붙인다'라는 의미로 생각하면 이해가 편하다.
문자형 붙이는 느낌
'문자를' + '붙여요' == '문자를붙여요'뜬금없지만 문자형을 다루는 방법은 여러가지가 있다.
- 붙이기 : tostring, join
- 분리하기 : split
Dataframe도 마찬가지로, 열이나 행을 기준으로 붙일 수 있다.
- index와 column이 같은 경우



- index와 column이 다른 경우



예시!
import pandas as pd
x = pd.DataFrame([['AX','AY'],['BX','BY']], index = ['A','B'], columns = ['X','Y'])
y = pd.DataFrame([['AX','AZ'],['CX','CZ']], index = ['A','C'], columns = ['X','Z'])일 때,
pd.concat([x,y]) # 기본적으로 행 row(axis=0)를 기준으로 합쳐지게 되어있다.X Y Z
A AX AY NaN
B BX BY NaN
A AX NaN AZ
C CX NaN CZ
pd.concat([x,y], axis=1) # 열 cloumn(axis=1)을 기준으로 합친다.X Y X Z
A AX AY AX AZ
B BX BY NaN NaN
C NaN NaN CX CZ
여러가지 팁
- 데이터 정리 때, index와 column을 서로 뒤바꿀 때
df.T # Transpose 사용- 데이터의 첫번째 행을 index로 사용하고 싶을 때
new_header = df.iloc[0] # grab the first row for the header
df = df[1:] # take the data less the header row
df.columns = new_header # set the header row as the df headerMerge

merge는 공통된 부분을 기반으로 합치는 용도!!! (concat도 합치긴 하지만, 서로 없는 index 및 column에 대해서 NaN으로 해서 합쳤다.)
df.merge('붙일내용', how='(방법)', on='(기준으로 삼을 feature)')
df = df.merge(df2, how='inner', on='칼럼1') # 이런식으로, 단 df를 기준으로 df2를 어떻게 붙이는지 종류가 여러가지이다.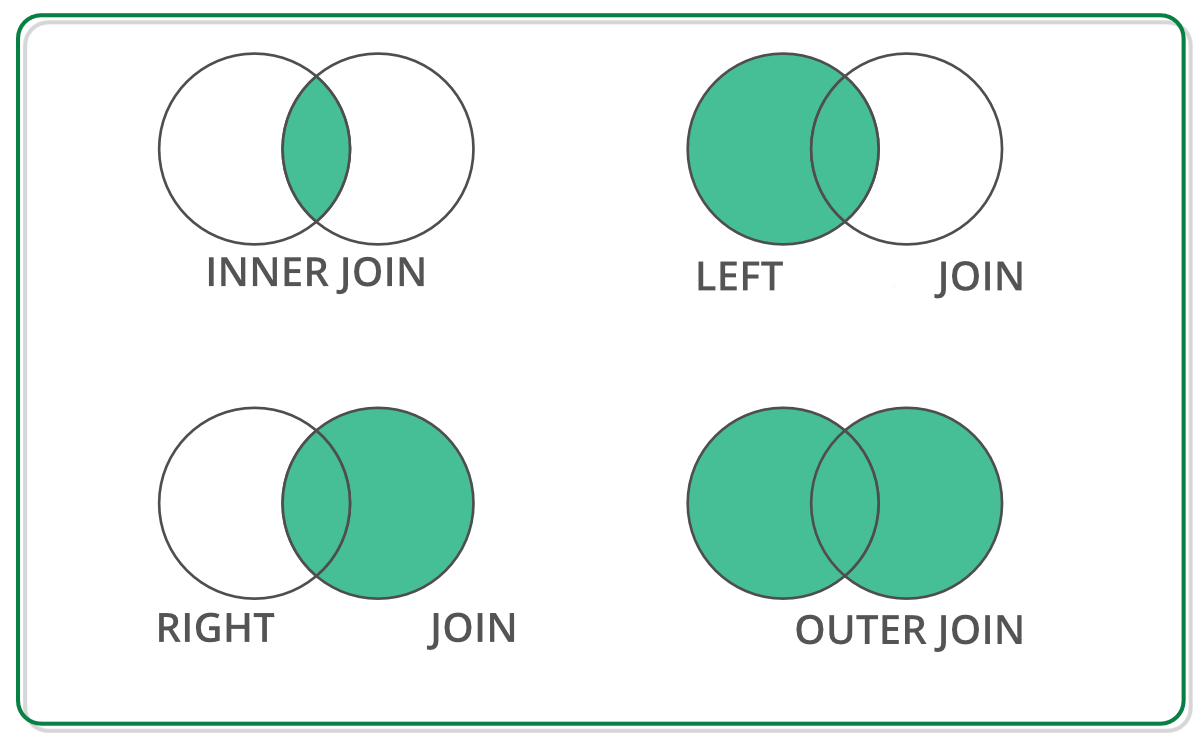
방법에 따라 이런식!!!
Conditioning(이건 예시로 가볍게 한번 보자)
우리가 이런 게 궁금해짐
- 주식 종목들의 평균 순이익률은 얼마일까
- 단, 순이익률이 - 인 종목은 제외하고 계산
- 테마별로
# 데이터프레임 필터링 예시
# type cast
df['순이익률'] = pd.to_numeric(df['순이익률'])
# 필터링 조건 (Condition) 설정
condition = (df['순이익률'] > 0) # Type Cast
# () 로 씌우는것에 주의
## condition 의 값을 출력을 통해 확인해보세요.
# [ ] 안에 컨디션을 설정하는 것으로, 컨디션의 값이 *TRUE*로 해당하는 부분의 데이터만 선택 할 수 있습니다.
df_subset = df[condition]
# 결과물을 확인
df_subset이렇게 동시에 적용도 가능하다. 그리고 condition 변수에 안넣고 그냥 바로 써도 무방. 대신 좀 지저분
condition = ( (df['순이익률'] > 0) & (df['순이익률'] < 10))isin
- 조금 tricky한 condition을 설정해보기(예시)
즉, '테마' 칼럼에서 '주류' 값을 갖는 애들만 골라줌df[df['테마'].isin(['주류'])]
이걸 condition으로 처리하면
df[(df['테마'] == '주류')]이렇게 쓰면 됨
Groupby
아래 조건 중 conditioning을 통해 2번까지는 완료
- 주식 종목들의 평균 순이익률은 얼마일까
- 단, 순이익률이 - 인 종목은 제외하고 계산
- 테마별로
이제 3번을 할 차례
종목 매출액 순이익률 종목명 테마
0 000080 6,243 5.17 하이트진로 주류
1 000890 205 2.15 보해양조 주류
2 005300 5,980 2.59 롯데칠성 주류
4 035810 4,108 16.00 이지홀딩스 육계
5 136480 2,613 2.51 하림 육계
라고 할 때,
df.groupby('테마').순이익률.mean()테마
육계 9.255000
주류 3.303333
Name: 순이익률, dtype: float64
위와 같이 테마에 따른 순이익률의 평균값이 나온다.
여기서 하나 또 알아두고 가면 좋은 점
df_subset.groupby('테마').mean()라고 하면
순이익률테마
육계 9.255000
주류 3.303333
과 같은 dataframe 형태가 출력된다. 왜 그런걸까?
일단 기본적으로 mean함수는 숫자형 칼럼에 대해서만 적용된다. 여기서는 '순이익률' 칼럼만 숫자형이라 이렇게 나오고
실제 다른 칼럼도 숫자형이 있다면 그 칼럼까지 추가해서 테마를 인덱스로 데이터프레임이 나오게된다.
자 이제 중요한 타이디 와이드 변환 과정 보자!!! 여기 잘 공부하자!!!
들어가기에 앞서 데이터 형태를 왜 굳이 바꿔야하나?
우리가 사용하는 라이브러리에 따라서 다른 형태의 데이터를 필요로 한다.
예를 들어 데이터 시각화에 쓰이는 Seaborn 라이브러리는 'Tidy 데이터'를 필요로 한다.
(물론 항상 그런 것은 아님)
Tidy 데이터 와 Wide 데이터
X,Y,Z에게 A,B라는 약을 투여해서 반응을 알아본다.

행에는 관측, 열에는 feature 흠... 아직 조금 헷갈린다... 우리가 흔히 보는 df들이 tidy형태인건가..? 좀더 생각해보자
wide한 데이터는 실제로 야생에서 볼 수 있는 형태
tidy는 이제 그걸 우리가 분석하기 용이하게 정리하는 느낌?? 이렇게 정리하면 index에 0부터 숫자가 들어갈테니 우리가 평소 보는 그 데이터모습은듯?
Wide에서 Tidy로
pandas의 melt 함수를 사용한다.
위의 X,Y,Z/A,B 테이블을 예시로 들면
### 행의 인덱스를 선택하고, 이를 행으로 새로 추가합니다.
tidy1 = wide1.reset_index() # rownames를 새로 설정 를 적용하면
index A B
0 X NaN 2
1 Y 16.0 11
2 Z 3.0 1
와 같이 된다. 이후
tidy는 한 행에, 한 observation을 갖게 하는 것
한 observation에는 어떤 값이 있어야할까
누가(id), 어떤 feature값을 가지는지(value) Column을 지정해주면 된다.
이를 melt로 표현하면 아래와 같다.
### 각 행에 대해서 (unique identifier)를 확인합니다.
### 한개의 "tidy" 한 열에 대해서 포함되어야 할 (기준이 되는) 데이터를 선택합니다.
tidy2 = tidy1.melt(id_vars = 'index', value_vars = ['A', 'B'])그러면
index variable value
0 X A NaN
1 Y A 16.0
2 Z A 3.0
3 X B 2.0
4 Y B 11.0
5 Z B 1.0
와 같이 된다. 그 후 column의 이름을 정리해주면 된다.
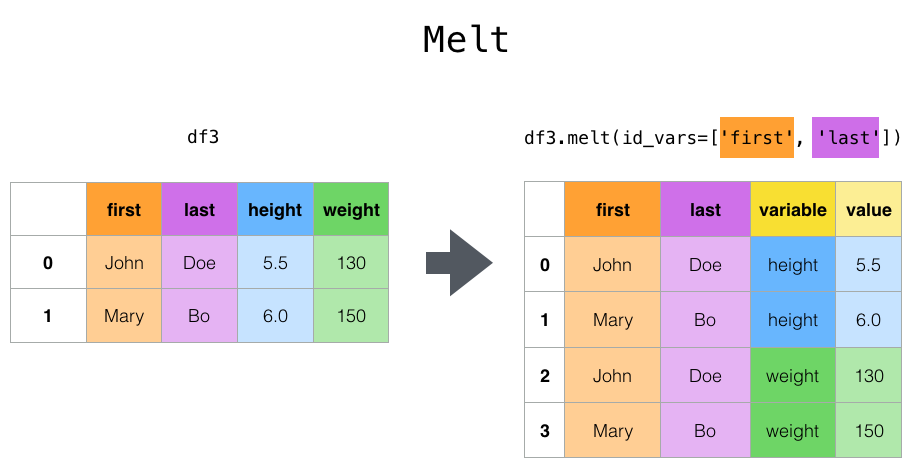
위 사진과 같은 느낌(흠... 아직 쫌 헷갈리네... 여기 진짜 더 공부해야겠다)
Tidy에서 Wide로
pivot_table 함수는 melt 함수의 반대 역할을 하는 함수!
# 파라미터에 대한 설명
# index: unique identifier
# columns: "wide" 데이터에서 column별로 다르게 하고자 하는 값.
# values: 결과값이 들어가는 곳 (wide 데이터프레임의 내용에 들어갈 값)
wide = tidy2.pivot_table(index = 'row', columns = 'column', values = 'value')그러면 다음과 같이 정리됨
column A B
row
X NaN 2.0
Y 16.0 11.0
Z 3.0 1.0
Tidy 데이터를 만드는 이유
예를 들면
seaborn과 같은 시각화 라이브러리에서 유용하게 사용될 수 있다.
import seaborn as sns
sns.catplot(x = 'row', y = 'value', col = 'column', kind = 'bar', data = tidy1, height = 2);
이렇게 tidy 형태여야 라이브러리를 이용하기 편리하다.
'💿 Data > 부트캠프' 카테고리의 다른 글
| [TIL]9.Bayesian Inference (0) | 2021.11.29 |
|---|---|
| [TIL]4.Basic Derivative (0) | 2021.11.27 |
| [TIL]2.Feature Engineering (0) | 2021.11.27 |
| [TIL]8.Confidence Intervals (0) | 2021.11.27 |
| [TIL]7.Hypothesis Test + (0) | 2021.11.26 |