목표
- 훈련/검증/테스트(train/validate/test) 데이터에 대한 이해
- 분류(Classification)와 회귀(Regression)의 차이점을 파악하고 문제에 맞는 모델 사용
- 로지스틱회귀(Logistic Regression)에 대한 이해
Train/Validate/Test data
Kaggle 'Titanic: Machine Learning from Disaster' 예시
import pandas as pd
train = pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/titanic/train.csv')
test = pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/titanic/test.csv')
print("train features: ", train.shape[1])
print("test features: ", test.shape[1])train features: 12
test features: 11
즉, test data는 target(label, 우리가 알고 싶은 정답) 변수가 하나 적습니다.
print("target col: ", train.columns.difference(test.columns)[0]) # 어떤 특성이 빠져있는지 확인target col: Survived
케글에서는 보통 train set 과 test set을 나눠서 제공합니다. 그런데 test set에는 target에 대한 정보를 제외해서 제공합니다.
일단 무작정 사람들이 test set을 통해 점수를 올리는 것을 막는 것도 있지만, 가장 큰 이유는 모델의 일반화 성능을 올바르게 측정하기 위하입니다.(사실 비슷한 이유)
그렇기에 우리는 train set의 일부를 validate set으로 나누어 우리가 만든 모델의 성능을 따로 검증해야합니다.
왜 validate set이 필요할까?
train set으로만 한번에 완전하게 학습시키는 것은 불완전하기 때문입니다. train set을 통해 다르게 튜닝된 여러 모델들을 학습한 후 어떤 모델이 학습이 잘 되었는지 validate set을 사용하여 선택하는 과정이 필요합니다.
즉, train set으로 여러 모델들을 학습(모델에 직접 관여)하고 validate set으로 모델을 선택하고, 좀더 조정을 한 후(모델에 간접 관여) test set에 대해서 단 한번 결과값을 시험해봅니다.
cf)만약 test set으로 모델을 선택하고 조절한다면, 그거 자체가 이미 test set에 특화된 모델을 고르는 것이기에 과적합에 기여하게 되는 거고 일반화 성능이 떨어지는 것입니다.
- train data : 모델을 fit하는 용도 == 문제집 학습
- validate data : 예측 모델을 선택하기 위해 오류를 측정하는 용도 == 모의고사
- test data : 일반화 오류를 평가하기 위함으로 선택된 모델에 대해 마지막에 한 번 사용, 훈련이나 검증과정에서 절대 사용X == 수능
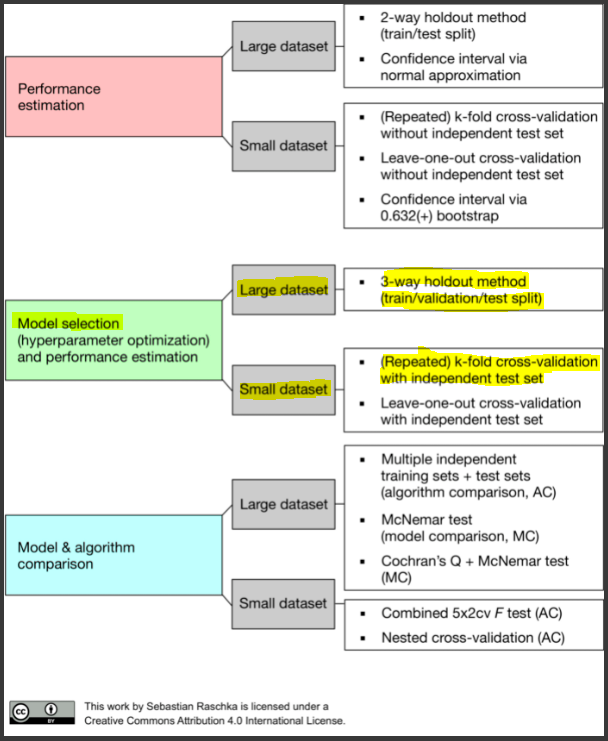
- 학습 모델을 개발 시, 모델 선택(Model Selection) 과정이 필수
- 하이퍼파라미터(Hyper parameter) 튜닝을 하게 되는데 튜닝의 효과를 확인하기 위해 val data(검증 데이터)가 필요
- test data로 절대 튜닝을 하면 안됨
- 데이터가 많은 경우엔 train/val/test 으로 나눠서 사용하면 되지만, 상대적으로 데이터 수가 적을 경우 K-fold cross validation을 진행할 수 있습니다.(단, 이 때도 test set는 미리 따로 두어야합니다.)
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size=0.2, random_state=2) # random_state는 선택
train, validation = train_test_split(train, test_size = 0.2, random_state=2) # 나누어진 train에서 한번 더 나눠서 valdation 생성
# 이후 features와 target을 정해주고 X, y 로 나눈다.
features =
target =
X_train = train[features]
X_val = validation[features]
X_test = test[features]
y_train = train[target]
y_val = validation[target]
y_test = test[target]또는
features =
target =
X = df[features]
y = df[target]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=2)분류(Classification)
- 분류문제는 회귀문제와 다른 기준으로 기준모델을 선정합니다.
- 회귀문제 : 보통 타겟 변수의 평균값을 기준모델로
- 분류문제 : 보통 타겟 변수의 최빈값을 기준모델로
- 시계열(time-series) : 보통 어떤 시점을 기준으로 이전 시간의 데이터를 기준모델로
분류 문제에서 최빈값을 기준모델로 두는 이유?
클래스 1과 0을 비율이 9:1인 학습 데이터를 가지고 모델을 만든다면 모델 결과값을 1로 고정해도 정확도가 90%가 나오게 된다. 그럼 이 모델은 정확도가 90% 이상이니 의미가 있는 모델일까? X
따라서, 우리는 모두 1로 둬도 90%가 나오니 이 90%보다 높은 값을 갖는 모델을 만들어야 '유의미'하다고 판단할 수 있다.(말 그대로 기준이 되는 것이다.)
# 최빈기준모델 만드는 예시
target = 'Survived' # 타이타닉 셋으로 예시
y_train = train[target]
y_tain.value_counts(normalize=True) # 0과 1 중 최빈값이 어떤건지 알기 위함0 0.625749
1 0.374251
# mode(): Return the highest frequency value in a Series.
major = y_train.mode()[0]
# 타겟 샘플 수 만큼 0이 담긴 리스트를 만듭니다. 기준모델로 예측
y_pred = [major] * len(y_train)분류에서의 평가지표(회귀와는 다른 평가지표 사용)
- 절대로 회귀평가지표를 분류 모델에 사용해선 안됩니다. 그 반대도 마찬가지
- 분류문제에서의 사용하는 평가지표 : 정확도(Accuracy)
$$Accuracy = \frac{올바르게 예측한 수} {전체 예측 수} = \frac{TP + TN} {P + N}$$
# 이런식으로 accuracy 구할 수 있음
from sklearn.metrics import accuracy_score
print("training accuracy: ", accuracy_score(y_train, y_pred))로직스틱 회귀(Logistic Regression)
로지스틱 회귀모델
$$\large P(X)={\frac {1}{1+e^{-(\beta_{0}+\beta_{1}X_{1}+\cdots +\beta_{p}X_{p})}}}$$
$$ 0 \leq P(X) \leq 1$$
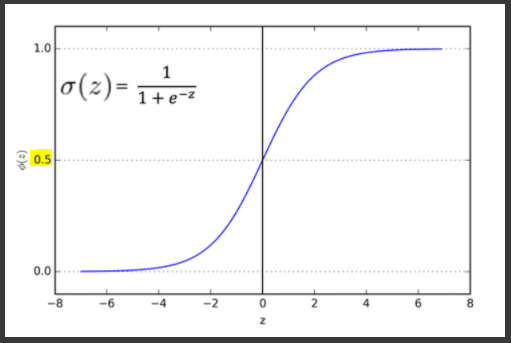
로지스틱회귀는 특성변수를 로지스틱 함수 형태로 표현합니다.(위에서 0.5를 기준으로 0 과 1로 나뉩니다.)
결과적으로 관측치가 특정 클래스에 속할 확률값으로 계산이 됩니다. 분류문제에서는 확률값을 사용하여 분류를 하게 됩니다.
Logit Transformation
- 로지스틱회귀 계수는 비선형 함수 내에 있어 직관적으로 해석하기가 어렵습니다.
- 이 때, 오즈(Odds) 를 사용하면 선형결합 형태로 변환이 가능해서 보다 쉽게 해석 가능
- 오즈(Odds) : 실패확률에 대한 성공확률의 비 == 성공확률/실패확률 == 클래스1에 속할 확률 / 클래스0에 속할 확률
$$Odds = \large \frac{p}{1-p}$$
p = 성공확률, 1-p = 실패확률
$$p = 1 일때 odds = \infty ,p = 0 일때 odds = 0$$
$$\large ln(Odds) = ln(\frac{p}{1-p}) = ln(\frac{\frac {1}{1+e^{-(\beta_{0}+\beta_{1}X_{1}+\cdots +\beta_{p}X_{p})}}}{1 - \frac {1}{1+e^{-(\beta_{0}+\beta_{1}X_{1}+\cdots +\beta_{p}X_{p})}}}) = \normalsize \beta_{0}+\beta_{1}X_{1}+\cdots +\beta_{p}X_{p}$$
- 로짓변환(Logit Transformation) : 오즈에 로그를 취해 변환하는 것
- 이를 통해 비선형형태인 로지스틱함수형태를 선형형태로 만들어 회귀계수의 의미를 좀더 쉽게 해석할 수 있습니다.
- 특성 X의 증가에 따라 로짓(ln(Odds))가 얼마나 증감했다고 해석 가능 ; X(특성) 1단위 증가 당 Odds는 exp(계수) 만큼 증가한다 해석 가능)
기존 로지스틱형태의 y 값은 0 ~ 1의 범위를 가진다면 로짓은 -∞ ~ ∞ 의 범위를 갖게 됩니다.

로지스틱 회귀 추가사항
# 다음과 같이 fitting
from sklearn.linear_model import LogisticRegression
logistic = LogisticRegression()
logistic.fit(X_train, y_train)
logistic.score(X_train, y_train) # 이렇게 하면 train set에 대한 정확도를 구할 수 있음
logistic.score(X_val, y_val) # 이렇게 하면 val set에 대한 정확도를 구할 수 있음추가 팁(여러 인코더 사용 예시)
! pip install category_encoders
from category_encoders import OneHotEncoder # scikitlearn에도 있긴한데, category_encoders꺼가 더 유용하고 사용하기 좋음
encoder = OneHotEncoder(use_cat_names=True) # 각 범주의 명을 컬럼에 사용하겠다는 뜻(cat== category)
X_train_encoded = encoder.fit_transform(X_train)
X_val_encoded = encoder.transform(X_val)from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean') # 결측치를 '평균'으로 채워주겠다.
X_train_imputed = imputer.fit_transform(X_train_encoded)
X_val_imputed = imputer.transform(X_val_encoded)from sklearn.preprocessing import StandardScaler
scaler = StandardScaler() # 각 컬럼의 단위를 맞추는 것 ; 표준화(scailing)
X_train_scaled = scaler.fit_transform(X_train_imputed)
X_val_scaled = scaler.transform(X_val_imputed)이런 과정을 train 과 val set에 적용 후 모델에 fit(여기서는 LogisticRegression)
마지막에 test set을 통해 최종 결과를 낼 때도 위 과정을 X_test에 해줘야합니다.
X_test = test[features]
X_test_encoded = encoder.transform(X_test)
X_test_imputed = imputer.transform(X_test_encoded)
X_test_scaled = scaler.transform(X_test_imputed)
y_pred_test = model.predict(X_test_scaled)
# 이런 식으로 :)'💿 Data > 부트캠프' 카테고리의 다른 글
| [TIL]28.Decision Tree(의사결정나무) (0) | 2021.12.26 |
|---|---|
| [TIL]27.Section2_sprint1 challenge (0) | 2021.12.24 |
| [TIL]25.Ridge Regression(능형 회귀) (0) | 2021.12.21 |
| [TIL]24.다중선형회귀(Multiple Linear Regression) (0) | 2021.12.21 |
| [TIL]23.Simple Regression(단순회귀) (0) | 2021.12.18 |